Overview
heteff is built around three generalized random forest
estimators:
The package is intentionally small. It assumes that the user has already defined an analysis table and wants a consistent way to:
- estimate heterogeneous effects,
- summarize the fitted forest into reusable tables,
- expose the dominant effect modifiers through a shallow explanation tree.
The goal is not to replace grf, but to make a narrow
subset of grf workflows easier to run repeatedly and easier
to communicate.
Observed data and notation
For each sample , let:
- be a vector of baseline covariates,
- be treatment or exposure,
- be the outcome,
- be an instrument when an IV design is used.
The package works with two observed-data structures.
Observational causal forest
The observational workflow targets the conditional average treatment effect:
This estimand asks how much expected outcome changes when treatment changes from 0 to 1, among samples with baseline profile .
In practice, grf::causal_forest() uses orthogonalization
and forest-based adaptive neighborhood weighting to estimate
without forcing the user to specify one global parametric interaction
model.
Survival causal forest
For right-censored outcomes, heteff uses
grf::causal_survival_forest(). At a user-specified horizon
,
the estimand is one of:
or
The first is a subgroup-specific restricted mean survival time difference up to horizon . The second is a subgroup-specific survival-probability difference at the same horizon.
These are useful because they turn a time-to-event problem into an estimand that can be compared across clinically interpretable subgroups.
Instrumental forest
The IV workflow uses grf::instrumental_forest() and
targets:
This is the local IV effect identified by instrument-induced variation in , conditional on . When the IV assumptions hold, this quantity can be interpreted as a subgroup-specific local causal effect.
The ratio form is important:
- the numerator measures how the instrument shifts the outcome,
- the denominator measures how the instrument shifts the exposure,
- their ratio scales the reduced-form association into a local causal effect.
Design assumptions
heteff does not prove design validity. It assumes the
design has already been chosen well enough that a heterogeneous-effect
analysis is sensible.
Observational assumptions
For the observational and survival workflows, the main assumptions are:
- consistency,
- no interference,
- conditional exchangeability given ,
- overlap or positivity.
In practical terms, this means the covariate set should be baseline-only, clinically defensible, and rich enough to capture major confounding pathways.
Instrumental assumptions
For the IV workflow, the main assumptions are:
- relevance: shifts ,
- exclusion: affects only through ,
- instrument independence given ,
- enough overlap and effective first-stage strength.
The package cannot guarantee these assumptions, but it does report a
compact check_table that includes first-stage correlation
and an F-statistic as a minimal diagnostic layer.
DAGs
The package ships with two compact design DAGs.
Observational DAG
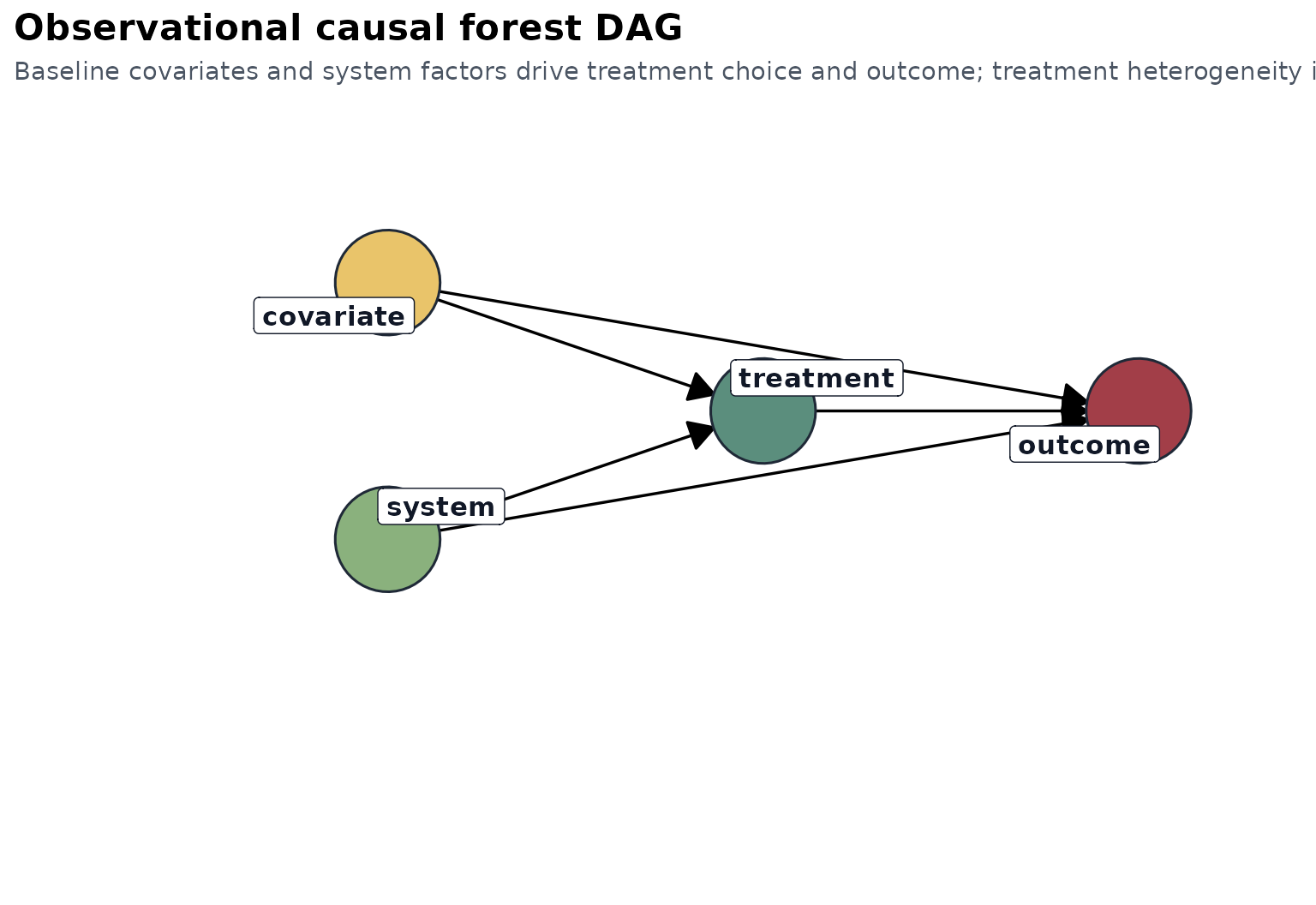
Interpretation:
- baseline covariates and system factors affect both treatment and outcome,
- the causal target is identified by adjusting for baseline ,
- subgroup heterogeneity is modeled as effect variation over .
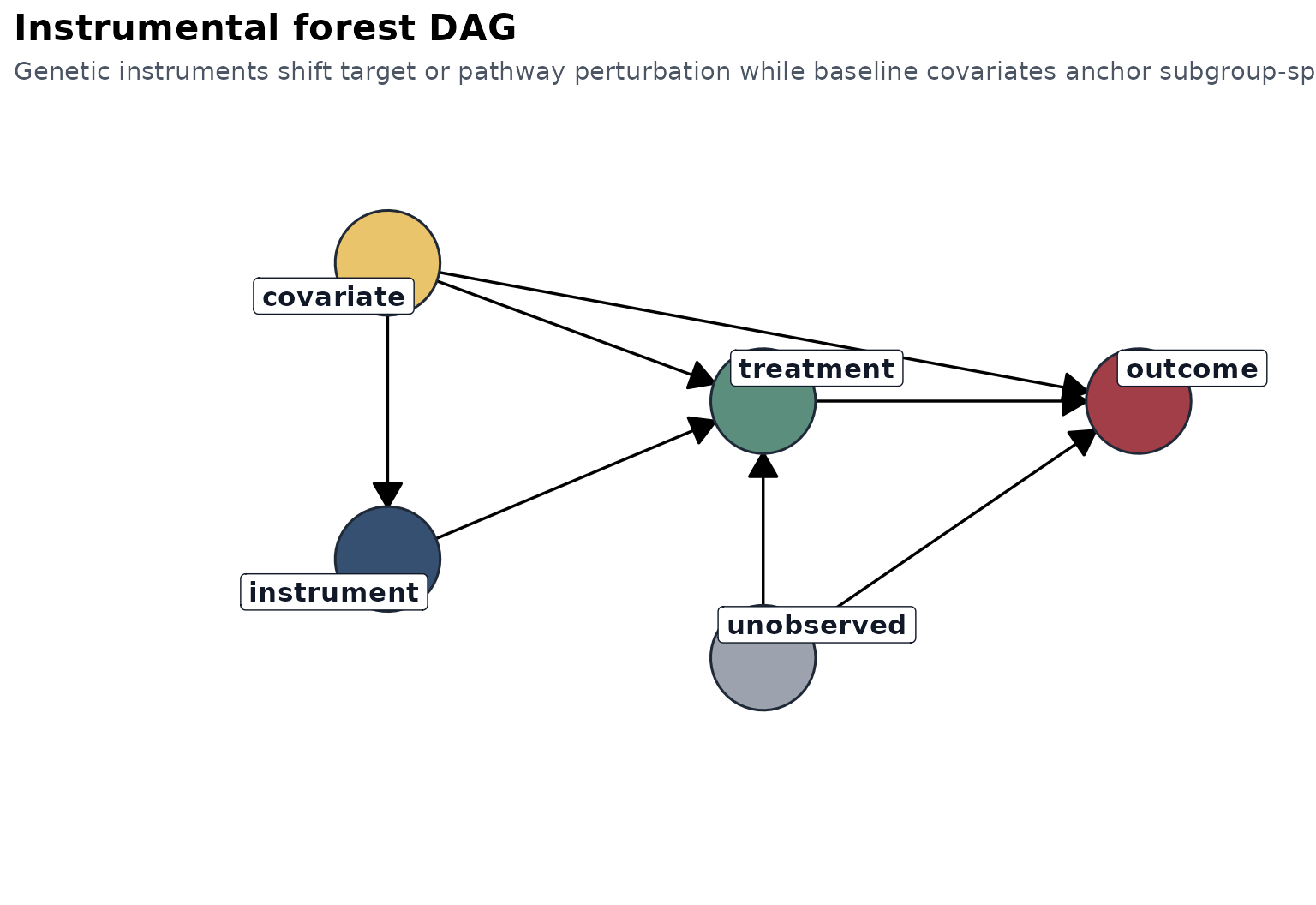
What the package computes
The package-level workflow is the same across estimators.
- Build the forest from one analysis table.
- Predict sample-level heterogeneous effects.
- Aggregate predicted effects into subgroup summaries.
- Fit a shallow explanation tree to the predicted effects.
- Rank candidates within subgroup when a
candidatecolumn is present.
This produces a shared output contract:
effect_tablesubgroup_tabletree_tableranking_tablecheck_tableestimand_tablevariable_importance
Explanation tree as a reporting layer
The explanation tree is not the forest itself. This distinction matters.
The forest is the primary estimator. It is flexible, local, and ensemble-based. The explanation tree is a secondary model fit to the predicted effects:
followed by a shallow regression tree:
This second-stage tree is used only to create readable subgroup rules. It is a communication layer, not a replacement estimand.
Why the package stays simple
The package does not attempt to expose all of grf. It
stays centered on three estimators because those three correspond to
three common design classes:
- treatment-effect heterogeneity in observational data,
- heterogeneous effects for right-censored survival outcomes,
- local IV heterogeneity in instrumental settings.
That constraint keeps the interface readable, the outputs stable, and the tutorials coherent.